

Most AI projects fail the moment they touch real company data

There is a belief spreading across many companies that AI adoption is mostly a technology challenge.
You choose the right model, deploy the right copilots, integrate the right tools, train employees to write better prompts and everything works.
They are completely wrong. Once they move from demos and pilots to the real world, they usually discover that the biggest obstacle is not the AI. It is the company’s own data.
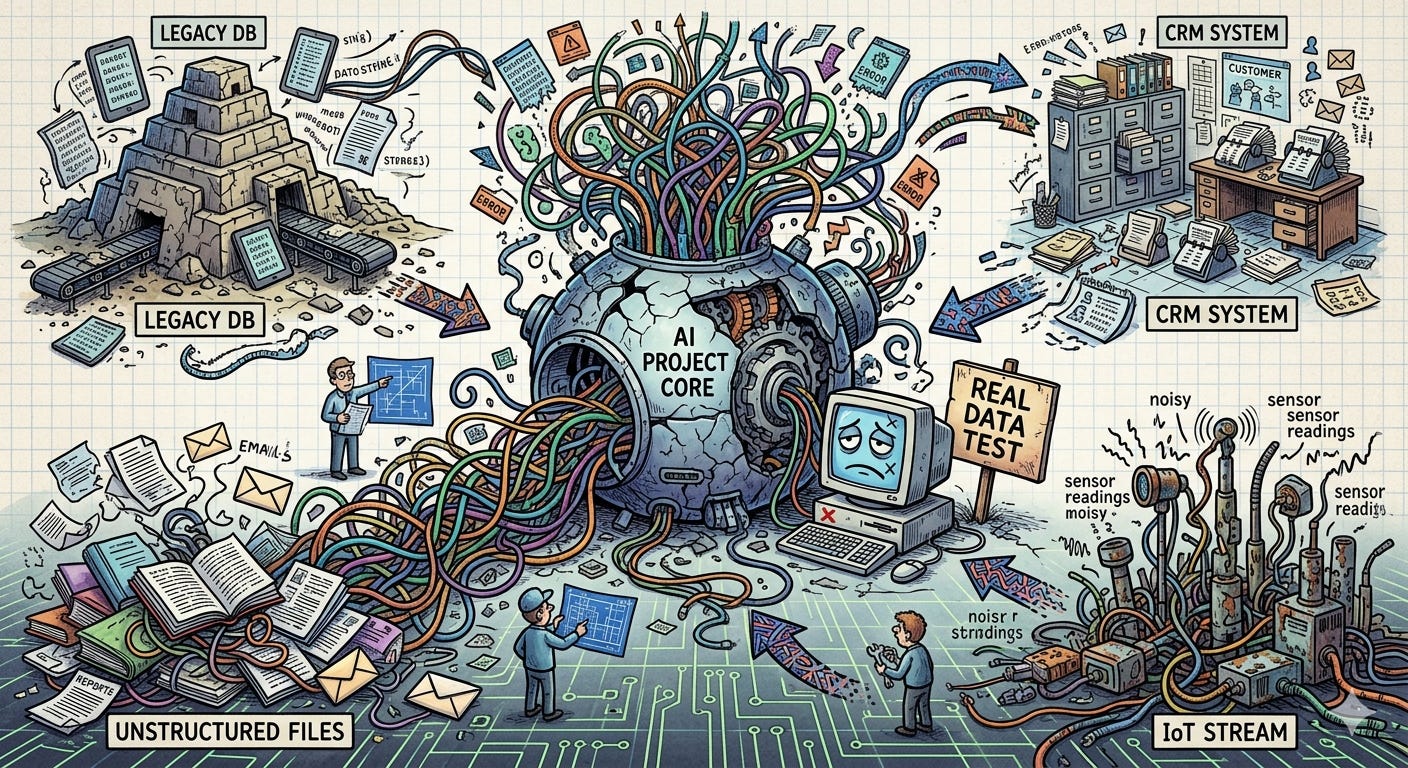
Most organizations spent years accumulating systems, platforms, spreadsheets, CRMs, dashboards, shared drives, unofficial reports, duplicated files, and disconnected workflows.
Each department optimized locally. Sales adopted one platform, finance another, operations built manual processes around excel files and marketing created its own databases.
Humans learned how to navigate this complexity over time and they know which spreadsheet is “the real one”, which report nobody fully trusts and which numbers need manual correction before putting them into an executive report.
AI does not know any of that and without context it simply processes the information received.
That’s normally the starting point for many AI initiatives to collapse.
A company asks an AI system to generate insights across operations, customers, finance, and projects. The AI connects to fragmented systems filled with duplicated records, outdated information, inconsistent naming conventions, and conflicting metrics and suddenly the outputs becomes unreliable.
Leadership starts questioning the technology but often the technology is simply exposing operational disorder that already existed.
AI is not creating the chaos and in fact is simply revealing it faster.
When AI is only summarizing documents, the risks are relatively small. But once agents begin executing workflows, recommending decisions, generating forecasts, prioritizing tasks, or interacting with customers, the quality of the underlying data becomes critical.
Bad data no longer creates minor inefficiencies. It creates bad decisions at scale and scale changes everything.
Before AI, humans acted as operational filters. Employees corrected mistakes manually, reconciled conflicting numbers during meetings, and compensated for broken processes using the knowledge accumulated over years.
AI has none of that context unless companies intentionally structure and govern it.
That is why so many organizations are discovering that their AI strategy is actually a data strategy in disguise.
The companies currently seeing the strongest AI results are rarely the ones deploying the highest number of tools. In many cases, they are simply the companies with cleaner operational foundations.
Their systems communicate better, with more standardized workflow and with clear data definitions.
Before scaling AI, fix your data
Before scaling AI, companies need to stop treating data as a sub product of operations and start treating it as infrastructure. That means identifying where critical information actually lives, eliminating duplicate sources, standardizing definitions across departments, and deciding which systems are the real source of truth.
If sales, finance, and operations use different versions of the same data, AI will simply amplify the inconsistency.
The second step is integration. Most organizations have useful information trapped across disconnected platforms, spreadsheets, shared drives, CRMs, ERPs, and collaboration tools.
AI only becomes reliable when context flows consistently between systems. Companies that succeed with AI usually invest heavily in connecting workflows and centralizing operational knowledge before automating decisions.
Finally, companies need governance and ownership.
Someone must be responsible for data quality, review processes, access permissions, and validation of AI-generated outputs.
Many organizations deploy AI without defining accountability, assuming the technology will somehow organize itself. It will not. Reliable AI depends on reliable operational discipline behind the scenes.
In conclusion
The organizations that will succeed over the next decade will probably not be the ones with access to the most advanced models.
The real advantage will belong to companies whose systems, workflows, and data can actually support intelligent automation reliably.
Because in the end, the most valuable layer in AI is not compute.
It is trust!
And trust starts with data quality!
Writing as someone building an AI-native business from scratch, so this one hits close. The line that stuck with me: the workarounds humans navigate intuitively but AI can't. That's the real killer — not the duplicate records (you can dedup those), but the undocumented judgment living in people's heads. That's not a data-cleanup problem, it's a knowledge-extraction one, and most "data governance" never reaches it.
The reframe I'd add: the mess is a property of when the business was born. Companies that grew before AI inherited 30 years of data across 20 systems — for them you're exactly right, cleanup is the bottleneck. But a business built AI-native from day one never inherits the debt; it grows one knowledge base as it goes. So the problem isn't "clean the mess," it's "never make it." Same AI, opposite starting point — two different games.
What strikes me the most here is how rarely the underlying and supportive operational components are talked about - when they have such a large impact on whether any of it works..